Active learning enables collaboration between the annotator and data scientist to intelligently select data points to label. It helps identify important data points that the annotator should label to rapidly improve model performance. Snorkeling complements active learning by helping partial automation of data label creation. It focuses on identifying easy data points that can be labeled programmatically, instead of by an annotator.
A key barrier for businesses’ adoption of machine learning is not lack of data but lack of labeled data. In Learn more with less data, we shared how active learning enables collaboration between the annotator and data scientist to intelligently select data points to label. Using this approach we can identify important data points that the annotator should label to rapidly improve model performance
Snorkeling complements active learning by helping partial automation of data label creation. It focuses on identifying easy data points that can be labeled programmatically, instead of by an annotator.
Background: What is Snorkeling?
Snorkel is a library developed at Stanford for programmatically building and managing training datasets.
In Snorkel, a Subject Matter Expert (SME) encodes a business rule for labeling data into a Labeling Function (LF). The LF can then be applied to the unlabeled data to produce automated candidate labels. Typically, multiple LFs are used to produce differing labels, and policies are defined for selecting the best final label choice. These policies include majority vote and a model-based weighted combination.
The labeling functions can be evaluated for coverage of the unlabeled training data. The SME can determine if gaps exist, and add additional LFs for those cases. The labeled training data can then be used to train or generate a classifier model. The purpose of this model is to evaluate the quality of the labeled dataset produced by Snorkeling versus a reference or gold labeled data set. This model is evaluated using manual labeled test data for performance analysis. This can be used as feedback to the SME to further tune the LFs.
The overall process is shown in the following figure.
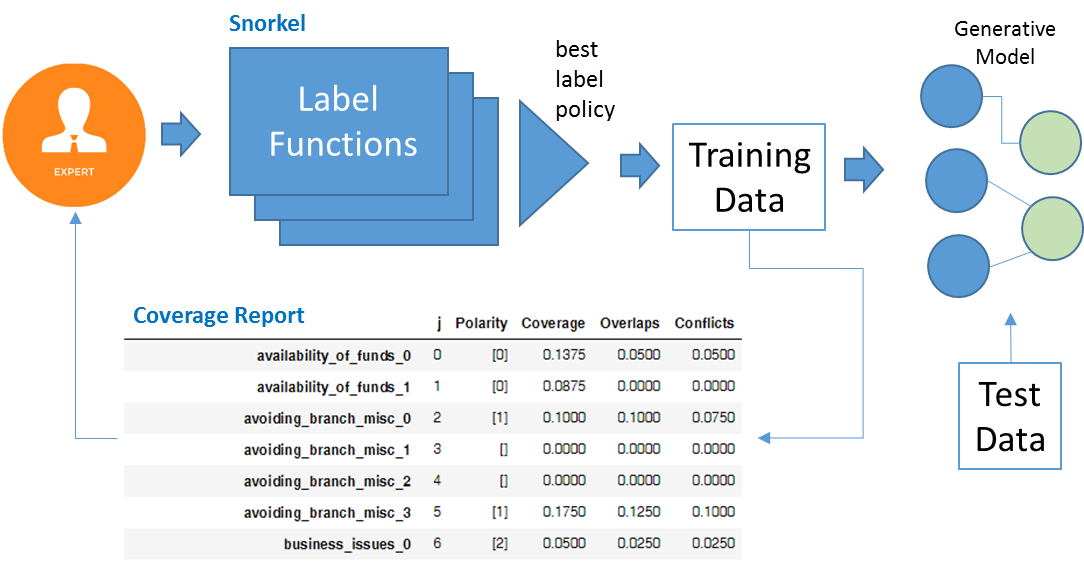
LFs can use different types of heuristics. For example, patterns in the content can be identified, such as keywords or phrases. Or attributes of the content such as the length or source of the content could be used. The SME determines the best LFs based on knowledge of the domain, data, and by iteratively improving the LFs to increase coverage and reduce noise.
LFs can use different types of heuristics. For example, patterns in the content can be identified, such as keywords or phrases. Or attributes of the content such as the length or source of the content could be used. The SME determines the best LFs based on knowledge of the domain, data, and by iteratively improving the LFs to increase coverage and reduce noise.
Because of the high cost and time consuming nature of producing manual labels, a variety of programmatic and machine learning techniques are used. Data scientists uses a combination of techniques such as Snorkeling, Active learning, and manual labeling, depending on the stage of ML development and types of data and the requirements of the training environment.
Why is Snorkeling valuable?
Snorkeling has two primary sources of value 1) Labor savings 2) Faster time to market
Labor savings
Applying Snorkeling can substantially reduce the amount of labor required. In one project, two annotators label 3K to 5K labels per week, and in another project, five annotators label approximately 2,000 customer interactions per week. A data engineer can create a set of Snorkel label functions in about one month for each project. The label functions can be run each week and the results can either be used to directly retrain the model, or reviewed by the annotators in less than half the time to annotate the unlabeled data.
Combining this approach with Active Learning allows the data scientist to create a high performing model with significantly reduced cost compared to using traditional data labelling approaches.
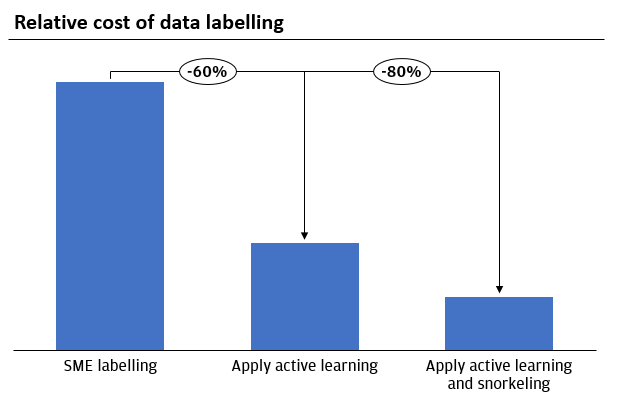
Applying Snorkeling can substantially reduce the amount of labor required. In one project, two annotators label 3K to 5K labels per week, and in another project, five annotators label approximately 2,000 customer interactions per week. A data engineer can create a set of Snorkel label functions in about one month for each project. The label functions can be run each week and the results can either be used to directly retrain the model, or reviewed by the annotators in less than half the time to annotate the unlabeled data.
Faster time to market
Using Snorkeling, we built a model on unseen data using heuristics and small labels, and augmented data using fine-tuned transformation functions. The team then built and deployed a model within 10 days – far faster than the traditional development cycle of 30 days or more. Separately, we analyzed that by training a model with a data set label using Snorkeling, we could improve model accuracy significantly.
Applying Snorkel
Industry solutions
In a study at Google [Bach et al 2019], data scientists used an extension of snorkeling to process 684,000 unlabeled data points. Each data sample was selected from a larger data set by a coarse grained initial keyword-filtering step. A developer wrote ten labeling functions. These LFs included:
- The presence of URLs in the content, and specific features of the URLs
- The presence of specific entity types in the content, like ‘person’, ‘organization’, or ‘date’, using a Natural Language Processing tool for Named-Entity Recognition
- The matching of the topic of the content with specific topic categories, using a topic model classifier
The model trained on the labeled data set from Snorkeling matched the performance of 80K hand labeled training labels, and were within 5% of the performance metric (F1 score) of a model trained on 175K hand-labeled training data points.
JPMC solution
Due to Covid-19 virus and lockdown, customers’ feedback and complaint pattern profoundly changed at unprecedented speed. To understand customer issues, we used Snorkeling to build machine learning using a small set of labels, heuristics functions and augmentation techniques team created a dataset and COVID specific model.
A data scientist with the project team, wrote 20 LFs for the Voice of the Customer (VoC) project, to label data for training the VoC model for COVID-19 and lockdown themed customer feedback. Below is an example using mock-up/synthesized data.
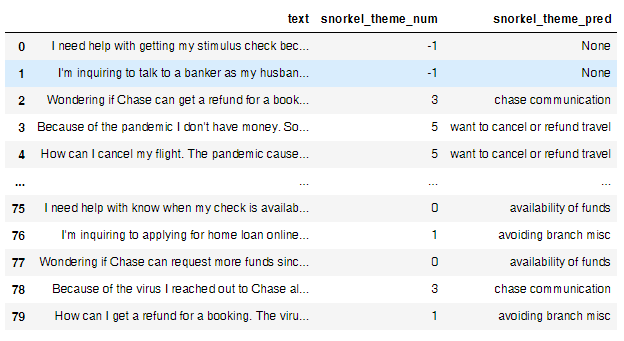
Using the model, the team identified complaint themes and the business took immediate action to solve customer problems.
Using the model, the team identified complaint themes and the business took immediate action to solve customer problems.
Learn More and Get Started
- An Overview of Weak Supervision https://www.snorkel.org/blog/weak-supervision(Opens Overlay)
- Snorkel.org – contains tutorials, source code
- AIX snorkel demo Jupyter notebook in OmniAI public folder
- Snorkel at github: https://github.com/snorkel-team/snorkel(Opens Overlay)
- Bach, Stephen H., et al. "Snorkel drybell: A case study in deploying weak supervision at industrial scale."(Opens Overlay) Proceedings of the 2019 International Conference on Management of Data. 2019.