Senatus AI is a Machine Learning on Code (MLonCode) toolkit developed by the CTO Applied Research team of J.P. Morgan Chase to supercharge the software development lifecycle. In this article, we focus on the code recommendation component of Senatus, and in doing so we expand on topics such as featurization of source code, minhashing, challenges in code retrieval and also how to speed it up from minutes to seconds utilizing cutting-edge algorithms such as "De-skew LSH".
Senatus, the ML for source code toolbox, sits at the heart of the transformation of the SDLC. It has inspired the ideation and creation of various projects, including but not limited to code recommendation, auto documentation, specification search and pattern detection.
The power of machine learning on source code (MLonCode)
Software Engineers, developers or programmers convert otherwise manual or complex processes to structured repeatable pieces of code. Given enough time, a software engineer is likely to automate as many tasks in their daily lives as they can for the benefit of saving one of the most precious resources: time.
With that in mind, envision this: you are writing a Python script to train a complex Generative Adversarial Neural Network architecture in order to generate realistic synthetic data. While you are typing in your integrated development environment (IDE), useful code recommendations start appearing, which are based on the context and stage you are at; this could be a recommendation for how other Generators are crafted for similar purposes, or a smart data transformation pipeline for that particular task. To your surprise, some of the recommendations come straight from the latest research papers which happened to post their code on Github, all presented in but a few split seconds. With a click of a button or a keyboard shortcut, your selection from the recommended snippets is intelligently pasted in your code, ensuring that it doesn’t break existing functionality. An automatic unit testing generation module updates the bank of unit tests, giving your new code the green light afterwards. To complete the experience, a code auto-documentation feature conveniently updates the docstrings for your function so that you don’t have to, based on how other similar functions had been described in the past. Machine Learning on Source Code (MLOnCode) has enabled you to produce faster, more accurate code, all at the comfort of a single IDE screen
Challenges
Large-scale codebases pose significant challenges to the development process, as engineers have to interact with millions of lines of code. To simplify and accelerate the process, a number of organizations have invested heavily in the area of Machine Learning on Source Code (MLonCode) to build tools that continuously learn from the ever-expanding codebases. Each tool introduced is tailored to address a specific use-case.
Code recommendation
In this article, we are going to delve in the Code Recommendation (S2) component of the Senatus toolchain. When building S2, we extended the concept proposed by Luan et al 5., which presented a flexible and powerful architecture for this task. Code similarity is the core of an effective and scalable code discovery and recommendation engine. We utilized cutting edge approaches such as locality sensitive hashing (LSH) in order to significantly improve on the original algorithm, both in speed and retrieval quality.
Under the hood
We introduce a number of key concepts in the field of MLonCode and walk you through our innovation, known as DeSkew LSH, that powers the code discovery and recommendation (S2) component of Senatus in this section.
Representation of Code
Code we write cannot be treated as textual information and used for comparison and recommendation. Code follows a well-defined syntax and structure and therefore we need a framework to capture this syntactic structure present in code.
There are two main types of syntax trees that can be used for representing code namely, Concrete Syntax Trees1 (CST) and Abstract Syntax Trees (AST). CST offers a tree-based representation defined by the grammars of a programming language, where the syntactic structure of the code, such as the whitespaces, parentheses, are preserved. Unlike CST, AST represents the syntactical information in a compact manner by removing all non-essential details.
Let's consider the following code snippet to understand how each of these code representations look like:
def add(x, y): z = x + y return z
By comparing both the CST and AST in the figure below, we can observe how the AST captures only the most essential aspects of the code. However, can we further simplify and generalise? Imagine if we could abstract away all the non-keyword tokens (variable names, method names, field names, literals, etc) and all the program-specific tokens, such that if we had two code snippets performing the same operation in two different programming languages with different set of tokens, it would look similar. The representation we then obtain is known as Simplified Parse Tree (SPT) proposed by Luan et al5.
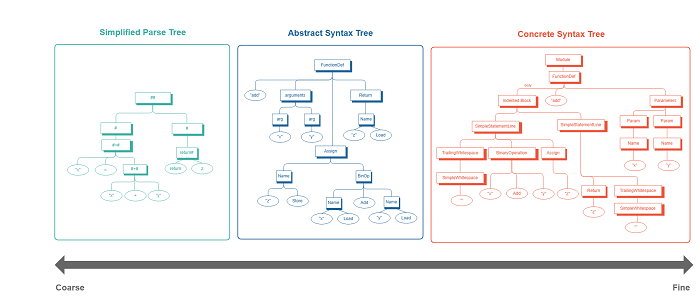
A diagrammatic representation of various syntax tree formats arranged in order of the level of abstraction. Simplified Parse Tree (SPT) is the most abstract representation, followed by Abstract syntax tree and finally Concrete Syntax Tree, which is the least abstract representation and provides detailed syntax such as white space.
This SPT representation is an example in effect of a code sketch, a way of representing code that focuses on the coarse level details and abstracts out more finer grained information that would negatively affect the generalization of the representation across different programs..
Featurization
In the previous section, we described how we represent code in Senatus using SPT and why specifically the SPT representation is used. Now the important question is, how do we use information present in the SPT for code recommendation?
The information present in the tree can be used by extracting features from the tree. The main idea in selecting the features is that given two similar code snippets, there should be a significant overlap between the two sets of features. The key is that the feature sets for two code snippets that are different only by their local variable names should be similar. Therefore, all the local variable names are renamed as '#VAR' while the global variables and method names remain the same.
The above modification is performed when we start extracting structural features from the tree that we believe can be useful and capture the relationship between different internal nodes. Referencing the featurization techniques from Luan et al 5., we extract four types of features by traversing through the SPT, namely:
- Token Features: This includes the value of the internal nodes present in the SPT.
- Parent features (Denoted by '>'): For every internal node, we want to capture its relationship to its parent node and its grand-parent node.
- Sibling features (Denoted by '>>'): It captures the relationship of every internal node to its sibling nodes.
- Variable usage features (Denoted by '>>>' ): In some cases, the same variable is used multiple times in the same code snippet in different contexts. We want to capture the different contexts in which the variable has been used.
Once we extract these features, we need to transform them so that we can perform numerical operations such as multiplication using these features. Hence, we perform another transformation which converts these feature to binary vectors.. The benefit of using this binary vector representation is that it provides flexibility to perform a variety of different computations and be used as input to different algorithms
In recent times, there has also been an increasing interest in developing alternative representations to this binary vector. These include continuous vector representations using frameworks such as code2vec2 , code2seq3, Infercode4, etc. It is an active area of research and one that we are actively working on.
Fast similarity Search with De-Skew locality sensitive hashing (LSH)
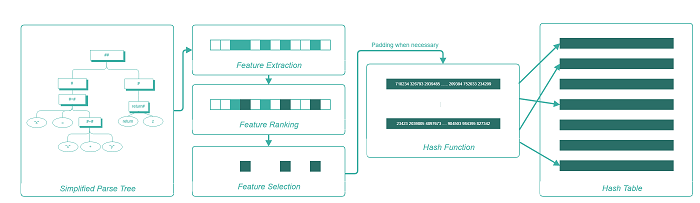
A diagrammatic representation of the feature extraction, feature ranking and feature selection pipelines using the Simplified Parse Tree (SPT) representation. The selected features are then passed to a hashing function to group together approximately similar pieces of code in a hash table
In the previous section we described one way to represent code by converting the code snippet into an simplified parse tree (SPT) and then converting that SPT in a binary vector that can be reasoned with by nearest neighbour search algorithms or machine learning models. Each binary vector is effectively a representation of the structural aspects of the corresponding code snippet. The next step towards our goal of recommending relevant code to developers is comparing those vectors and presenting the most similar vectors from our code repository to the developer. The innovation we present in this section is a method that greatly accelerates this lightweight search functionality from linear time complexity to sub-linear time, which makes all the difference for large-scale search over massive code repositories at JPMC scale.
The key questions we solve in this section is firstly, what measure of similarity should we use to compare these binary feature vectors that we have chosen to represent our code? And secondly, how do we compute the similarity between potential hundreds of thousands, if not millions, of vectors in a way that will still permit sub-second response to a developer query?
There is a well known similarity metric, the Jaccard similarity, for computing the similarity of two sets based on their contents. Jaccard similarity is the ratio of the sizes of the intersection and union of two sets that we wish to compare, which in our case would be two binary feature vectors. The equation for the Jaccard similarity is given below for two code snippets F(m1) and F(m2) where F(∙) is a function that takes a code snippet and returns the binary feature vector representing its SPT tree.
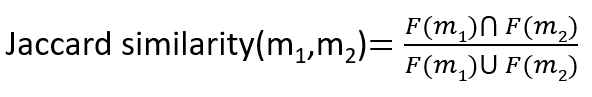
Jaccard similarity is biased towards shorter code snippets. Imagine that m2 is a much large code snippet that m1. The union operation on the denominator of the above equation will therefore be much larger in this case as compared to the case where m2 is roughly the same size as m1. This phenomenon is illustrated in the diagram below:
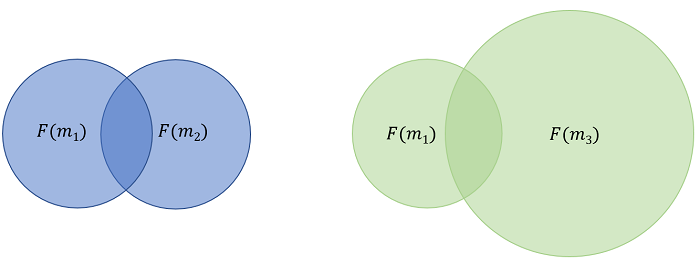
Two sets of Venn diagrams aimed at portraying the bias of the jaccard similarity metric towards shorter snippets of source code. The diagram on the left represents the overlap between two similar sized source code snippets while the one on the right represents the overlap between a small and large source code snippet. In both cases, the intersection of the 2 sets remains the same but the union is larger for the case where there are longer snippets. As a result, the jaccard similarity for a small snippet will be higher than that of a long snippet although the overlap is the same.
The above diagram visualizes the sets (i.e. binary vectors) as circles, with their intersections illustrated with the more darkly shaded region. To overcome the bias of Jaccard similarity to smaller sets, we can instead compute similarity using the containment score, defined below:
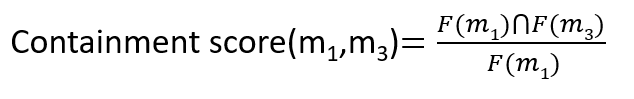
In fact, taking the dot product of the binary vectors is tantamount to taking the containment score as the cardinality of the query does not effect the ranking. We are measuring the fraction of the retrieved snippet F(m3) that is present in the query snippet F(m1). Unfortunately we now face the opposite problem, specifically the containment score is biased to longer snippets, as those snippets will have a greater opportunity of matching the features present in our smaller query set. For code-to-code recommendation that is useful to a user, ideally we want retrieved snippets to only slight extend the query snippet, adding on a small additional amount of useful functionality. In our research we have found that a typical sourcecode repository adheres to a power law in snippet length (show in the diagram below).
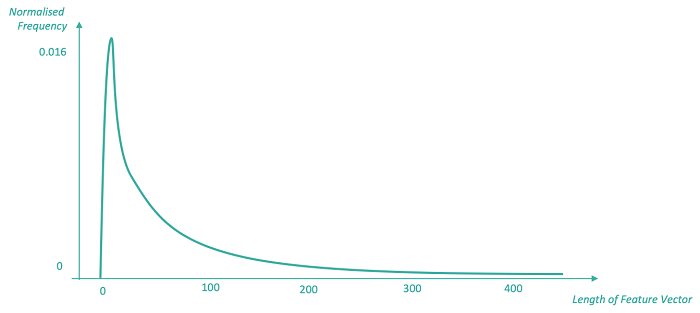
The distribution of snippet length in a repository follows a power law distribution. As a result, techniques such as LSH cannot be directly applied due to the skew-ness of the data. This motivates the use of various feature pre-processing steps to deskew the data distribution
How do we avoid this bias on snippet length while also achieving computationally efficient search over large sourcecode repositories? We introduce our innovation dubbed DeSkew-LSH that de-skews the data while applying the computationally attractive properties of a field known as locality sensitive hashing (LSH) to enable fast (sub-linear time) search. We describe the DeSkew part of DeSkew LSH before we dive into the LSH part.
For counteracting the bias to longer code snippets we introduce a novel feature ranking, feature selection and padding mechanism for minhash-LSH. The intuition behind this approach is to a) for longer feature vectors, reduce the feature vectors to a user-specified maximum length by feature selection (i.e. removing features with lower relevance as indicated by a feature scoring function) and b) for shorter feature vectors, pad those with random values so that their length is increased to a user-specific maximum length.
For the feature scoring function, we propose two variants distinguished by their locality (i.e. global or local) - Normalized sub-path frequency (NSPF) and Inverse Leaves Frequency (ILF). NSPF divides the frequency of a feature in the query against the total count of that feature in the code repository. This has the effect of ranking more common features lower in the ranking. In contrast ILF computes the inverse of the leaf node frequency within the query SPT only, which removes the dependence on the background code repository and ranks the common features on a level that is local to a given code snippet.
The scored features are ranked and then feature selection is applied to remove irrelevant features. We propose two feature selection methods that use the scores from NSPF or ILF. Our first feature selection method is called Top-K, and simply forms a new feature vector from the highest ranked K features in the original feature vector. Mid-N percentile, in contrast, removes the top and bottom N percentile of the feature vector, retaining the remainder. Having normalised the feature vectors in our collection to a fixed length, we then apply minhash LSH.
Without delving deeply into the mechanics of minhash for containment score as there are many great tutorials online 6, effectively minhash condenses binary feature vectors into much shorter length signatures in such a way that those binary vectors with similar containment score will receive similar minhash signatures. This means that we can use our shorter length minhash signatures as a proxy four our original much higher dimensional binary feature vectors, saving memory and computation. However, we want to go one-step further and achieve sub-linear search time. How do we achieve sub-linear time search with our signatures? Hashing is the answer! Locality sensitive hashing (LSH) provides a formal framework for chunking up (splitting) the minhash signatures in a way that gives a high probability of collision to those signatures having a containment score over a given similarity threshold. In contrast, for those signatures with a similarity lower than the threshold, there will be a much lower probability that they will collide in the same hashtable buckets. The hashing of featurized code snippets into hashtable buckets is illustrated in the diagram below.
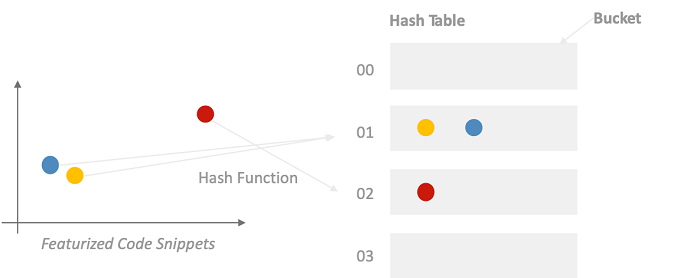
A diagrammatic representation of the hashing operation used to group together similar snippets of source code. Data points that are closer to each other in the feature space fall under the same bucket in the hash table while others are grouped in a different bucket.
To form a hash key from a minhash signature we apply SHA-1 to each signature chunk. In the above diagram, the blue and yellow circles represent code snippets that have a very high containment score, and are therefore very similar, sharing many of the same structural features. In contrast, the red circle is very dissimilar to the blue and yellow snippets, being further away in feature space. We see on the right that minhash-LSH provides the correct bucketing that respects the similarity relationships, with the blue and yellow snippets going into the same bucket (01) and the red circle going into another bucket (02). To find similar snippets to our query we therefore only need to generate the minhash signature for our query and then inspect only those buckets with the keys indicated by the minhash signature. Typically the number of snippets in any bucket is much less than the total number of snippets in the code repository, thereby facilitating the sub-linear time search that we desire
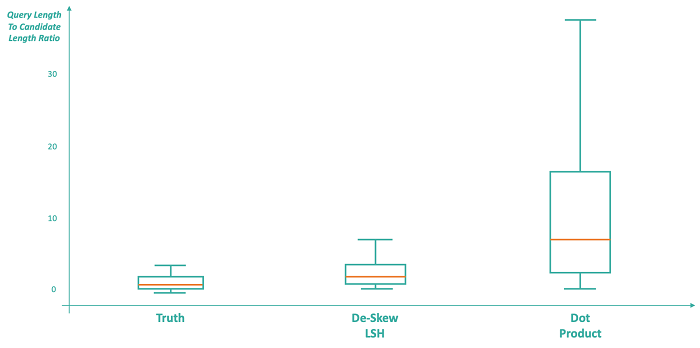
Comparison between ground-truth, deskew lsh and dot product results in relation to the length of snippet retrieved for a certain length of query snippet. The results portray the ratio between the length of retrieved snippet to the length of the query snippet. The closer the ratio to the ground truth, the better.
The above diagram shows that the ratio of the query snippet length to the length of the groundtruth code snippets in the CodeSearchNet corpus (https://github.com/github/CodeSearchNet) is mimicked closely by the ratio of the query length to the length of the the retrieved code snippets. This means that Senatus is able to return snippets of approximately the correct length to provide a useful recommendation for any given query, as compared to the dot product approach (shown on the far right), which has a much higher variance of the length of the retrieved snippets
Future
Senatus’s code discovery and recommendation engine promotes code re-use, which enhances code consistency and reduces time spent on tackling solved problems. For example, finding an established way to train a stable Generative Adversarial Network (GAN) and feature engineering for natural language processing.
Our proposed approach enables Senatus to harness insights with scalability in mind. It lays the foundation for other capabilities of Senatus, namely, code duplication, code auto-documentation, specification searches at scale. More details on those in the upcoming posts.
We’re looking forward to open source Senatus and seeing what the broader technology community builds with it!
How to Cite
If you find this blog post useful and wish to cite the article, the bibtex can be found below:
@INPROCEEDINGS{9796316,
author={Silavong, Fran and Moran, Sean and Georgiadis, Antonios and Saphal, Rohan and Otter, Robert},
booktitle={2022 IEEE/ACM 19th International Conference on Mining Software Repositories (MSR)},
title={Senatus - A Fast and Accurate Code-to-Code Recommendation Engine},
year={2022},
volume={},
number={},
pages={511-523},
doi={10.1145/3524842.3527947}}
Acknowledgements
We would like to thank our peer-reviewers Sanket Kamthe and Solomon Adebayo for their valuable feedback, as well as a special thank you to Brett Sanford for his continuous support.
References
1. Concrete Syntax Tree (CST) parser and serializer library for Python (https://github.com/Instagram/LibCST). The diagram has been simplified for visualisation purposes.
2. Alon, Uri, et al. "code2vec: Learning distributed representations of code." Proceedings of the ACM on Programming Languages 3.POPL (2019): 1-29.
3. Alon, Uri, et al. "code2seq: Generating sequences from structured representations of code." arXiv preprint arXiv:1808.01400 (2018).
4. Bui, Nghi DQ, Yijun Yu, and Lingxiao Jiang. "InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees." arXiv e-prints (2020): arXiv-2012.
5. Luan, Sifei, et al. "Aroma: Code recommendation via structural code search." Proceedings of the ACM on Programming Languages 3.OOPSLA (2019): 1-28.
6. Example tutorial: the Mining Massive Datasets book (http://www.mmds.org/)