Quantum computing is poised to revolutionize computational finance. Among many quantum computing algorithms proposed to date, Quantum Approximate Optimization Algorithm (QAOA) is one of the most commonly considered due to its ability to tackle a wide class of combinatorial optimization problems from graph coloring to portfolio optimization. While QAOA is hard to analyze theoretically, simulation can be used to gain understanding of QAOA performance. Such numerical studies are of particular importance in optimization, since only a handful quantum algorithms with provable speedups are known. For a numerical scaling analysis to be robust, it must consider sufficiently large systems. This motivates the use of high performance computing for these simulations.
QOKit: Simulating QAOA on GPUs
To study QAOA performance, Global Technology Applied Research at JPMorgan Chase in collaboration with the U.S. Department of Energy’s (DOE) Argonne National Laboratory developed QOKit—a Python library implementing a fast QAOA simulator, along with a set of tools to apply it to commonly considered problems. It can run on any platform from a single CPU to a GPU cluster with support from the NVIDIA cuQuantum library. A novel precomputation step allows to speed up the simulations by up to 7 times. QAOA is composed of several algorithmic steps, each with its set of parameters. To obtain a good quality solution using QAOA, one must find good parameter values for a particular problem and run a large enough number of steps. Using classical simulation algorithms, we can obtain expected quality of the solution for given parameter values. Many algorithmic steps are often required to get adequate performance, leading to deep quantum circuits.
Figure 1: Time to simulate QAOA MaxCut statevector on CPU (left) and GPU (right) using different libraries
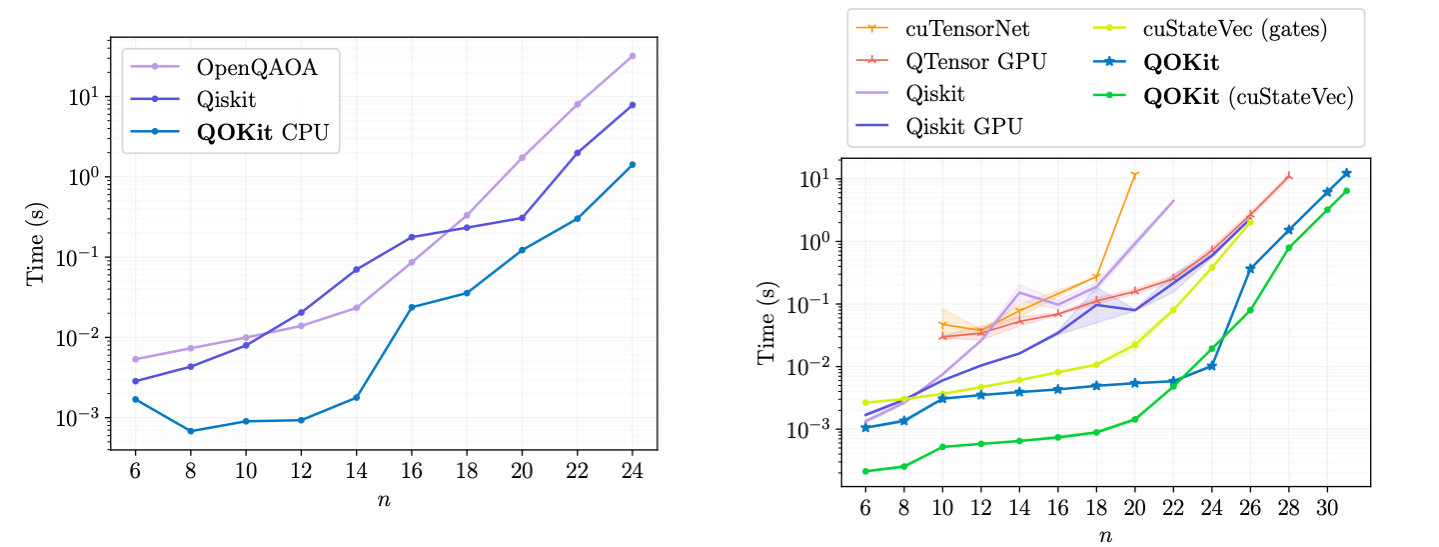
Figure 1: Time to simulate QAOA MaxCut statevector on CPU (left) and GPU (right) using different libraries.
Various classical methods have been developed to simulate quantum computers. Among the most potent is the method centered around tensor network contraction. For these algorithms, leveraging GPUs can accelerate the simulation by factors of 100 or more.
However, tensor network algorithms are best suited for low-depth QAOA circuits. To study QAOA in the regime with high-quality solutions, we need to simulate large-depth circuits. In this case, statevector simulation is more efficient.
The team from Global Technology Applied Research, JPMorgan Chase implemented a high-performance simulator using a combination of Python, custom C module and GPU kernels. On single-CPU benchmarks, our simulator outperforms commonly considered simulation packages, as shown in Figure 1 (left).
A key part of the algorithm is splitting the simulation into pre-computation and evaluation parts. In particular, the cost operator of QAOA is always diagonal and can be stored efficiently and reused for each evaluation.
In addition, we compare the GPU performance of our simulator against other state-of-the-art simulators on a single NVIDIA A100 Tensor Core GPU. Our benchmarks measure the time to simulate one layer of QAOA for LABS problem for various number of qubits n. The results are shown in Figure 1 (right).
We implement the pre-computation approach on the GPU and compare its impact on the time of simulation. In addition to our own gate application code, we combine the pre-computation with gate application that uses the NVIDIA cuStateVec library. This approach allows to improve simulation even further, especially for small problem sizes.
To scale up the simulation, QOKit was deployed on a distributed system with many GPUs. The challenge in the distributed simulation is the all-to-all communication pattern. The same problem occurs when implementing distributed Fast Fourier Transform. In our work, we compared two implementations of distributed simulation: with MPI-only communication and cuStateVec communication. The MPI-only version uses MPI_Alltoall call to implement the communication. In contrast, the cuStateVec uses a custom communication mechanism in the distributed index bit swap feature. This communication combines global MPI communication and local peer-to-peer communication between GPUs that are located on the same node. We see that cuStateVec provides much better communication timings (as shown in Figure 2).
Figure 2: Time to simulate QAOA LABS statevector using Argonne’s Polaris supercomputer
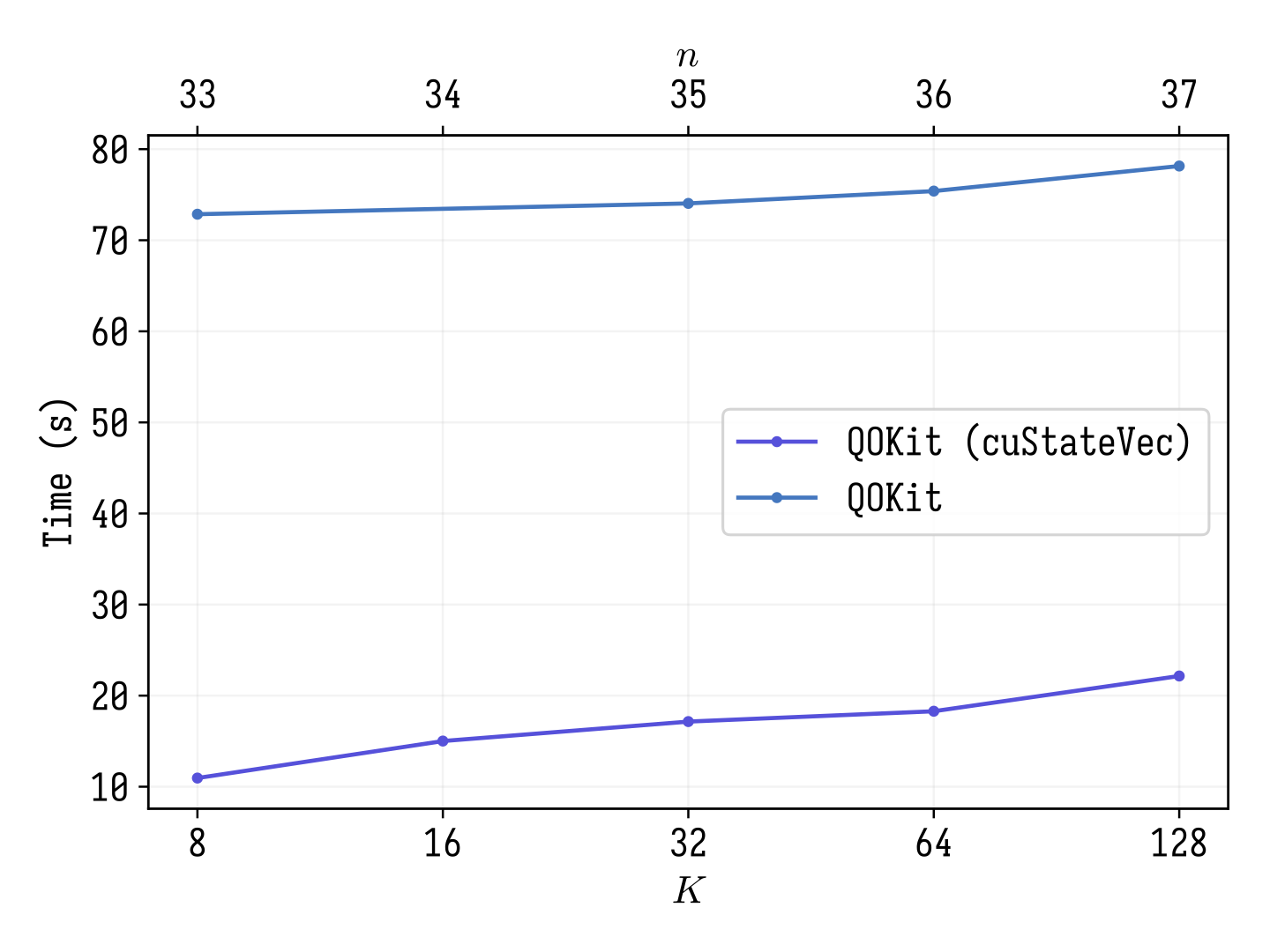
Figure 2: Time to simulate QAOA LABS statevector using Argonne’s Polaris supercomput
Simulation of QAOA on a GPU-accelerated supercomputer enabled the discovery of scaling advantage for QAOA
We used the QOKit library to evaluate QAOA scaling on a classically intractable problem called Low Autocorrelation Binary Sequences (LABS). Argonne Leadership Computing Facility resources allowed us to scale the simulation to 40 qubits using up to 1,024 GPUs per simulation. This was a key step to improve the confidence in the scaling of QAOA performance. The details of the scaling study can be found here.
“This unique demonstration of quantum algorithmic speedup with QAOA would not have been possible without our GPU simulator running at scale on Polaris supercomputer hosted at Argonne Leadership Computing Facility,” says Marco Pistoia, Managing Director, Distinguished Engineer, Head of Global Technology Applied Research, Head of Quantum Computing at JPMorgan Chase.
“The main motivation for creating supercomputing facilities like Argonne Leadership Computing Facility (ALCF) is to enable such tour-de-force numerical studies. It is gratifying to use our NVIDIA GPU-based Polaris supercomputer to enable algorithmic advancements in quantum computing,” says Yuri Alexeev, Principal Project Specialist at the Argonne National Laboratory.