Introduction
Chatbot has emerged to be one of the most popular interfaces given the improvement of NLP techniques. Within this big family, FAQ bot is usually designed to handle domain-specific question-answering given a list of pre-defined question-answer pairs. From the machine learning standing point, the problem could be further translated as “find the most similar question in database matching user’s question”, or something we called Semantic Question Matching. In this post, we will have a step-by-step tutorial for building a FAQ bot interface using Sentence-BERT and ElasticSearch.
Matching Logic
To solve the semantic question matching, there are generally two directions to go. One is to use the Information Retrieval approach which treats the pre-defined FAQs as documents and the question from users as the query. The advantage of this search-based approach is that it’s in general more efficient and scalable. Running this system on 100 FAQs vs 1 million FAQs usually won’t have a significant difference in inference time (this may still depend on the algorithm you use. For example, BM25 will be much faster than a ranking model). The other approach is to use a classification model which takes user question and a candidate FAQ as a question pair, then classify whether they are the same question or not. This method will require the classification model to run through all the potential FAQs with the user question to find the most similar FAQ. Comparing with the first approach, it could be more accurate but takes more computation resources during inference. In the following parts, we will focus on adopting the search-based method that computes the semantic embedding on both the user question and FAQs to select the best match based on their cosine similarity.
Sentence-BERT for Question Embedding
BERT types of models have been able to achieve SOTA performance on various NLP tasks1. However, BERT token level embeddings could not be transformed directly into a sentence embedding. A simple average of token embedding or just use [CLS] vector turns out to have poor performance on Textual Similarity tasks.
The idea to improve BERT sentence embedding is called Sentence-BERT (SBERT)2 which fine-tunes the BERT model with the Siamese Network structure in figure 1. The model takes a pair of sentences as one training data point. Each sentence will go through the same BERT encoder to generate token level embedding. Then a pooling layer is added on top to create sentence level embedding. Final loss function is based on the cosine similarity between embeddings from those two sentences.
Figure 1: Sentence-BERT (SBERT) with Siamese architecture
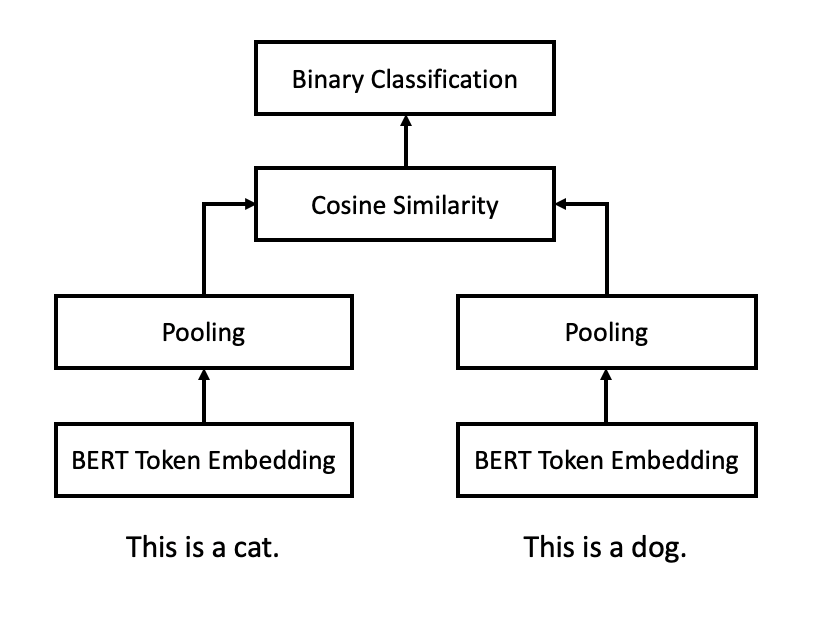
According to SBERT paper, fine-tuned SBERT could significantly outperform various types of baseline such as averaging GloVe [3] or BERT token embeddings in terms of Spearman rank correlation of sentence embeddings on textual similarity data set.
According to SBERT paper, fine-tuned SBERT could significantly outperform various types of baseline such as averaging GloVe3 or BERT token embeddings in terms of Spearman rank correlation of sentence embeddings on textual similarity data set.
The author team has also released a python package called “sentence-transformer” which allows use to easily embed sentences with SBERT and fine-tune the model based on a Pytorch interface. Following the GitHub link (https://github.com/UKPLab/sentence-transformers), we could download the package by:
```
pip install -U sentence-transformers
```
Then it’s straightforward to use a pre-trained SBERT model to generate question embedding:
```
from sentence_transformers import SentenceTransformer
sentence_transformer = SentenceTransformer("bert-base-nli-mean-tokens")
questions = [
"How do I improve my English speaking? ",
"How does the ban on 500 and 1000 rupee notes helps to identify black money? ",
"What should I do to earn money online? ",
"How can changing 500 and 1000 rupee notes end the black money in India? ",
"How do I improve my English language? "
]
question_embeddings = sentence_transformer.encode(questions)
```
The output of the “encode” method is a list with the same length as input “questions”. Each element in the list is a sentence embedding for that question which is also a NumPy array with a dimension of 768. Noted that 768 is the same size as general BERT token level embedding.
Dense Vector Search in ElasticSearch (ES)
Now we have a way to generate the question embedding that captures the underlying semantic meaning. The next step is to set up a pipeline for matching the user questions using the question embedding. To achieve this, we’d like to introduce a famous concept called ElasticSearch. This is one of the most well-known search engine based on Lucene which is scalable and easy to use. After its version 7.3, ES has released the dense vector data type which allows us to store our question embeddings as well as similarity match.
If you don’t have ES in your environment, you could download and install it following this link from its official website (https://www.elastic.co/downloads/elasticsearch). This will start a local ES instance and accessible through “localhost:9200”. As we use Python for this tutorial, a Python ES client is needed before we start:
```
pip install elasticsearch
```
There are generally two steps using ES: Indexing and Querying. In the indexing stage, we first create an “index” which is a similar concept as “table” in a rational database using the following code. All the pre-defined FAQs will be stored in this index.
```
from elasticsearch import Elasticsearch
es_client = Elasticsearch("localhost:9200")
INDEX_NAME = "faq_bot_index"
EMBEDDING_DIMS = 768
def create_index() -> None:
es_client.indices.delete(index=INDEX_NAME, ignore=404)
es_client.indices.create(
index=INDEX_NAME,
ignore=400,
body={
"mappings": {
"properties": {
"embedding": {
"type": "dense_vector",
"dims": EMBEDDING_DIMS,
},
"question": {
"type": "text",
},
"answer": {
"type": "text",
}
}
}
}
)
create_index()
```
In ES, there is a concept called “mapping” during index creation. It is similar to define a table schema for table creation. In our tutorial, we create an index called “faq_bot_index” with three fields:
- embedding: a dense_vector field to store question embedding with a dimension of 768.
- question: a text field to store the FAQ.
- answer: a text field to store the answer. This field is just a place holder and not relevant to this tutorial.
Once we have the index created in ES, it’s time to insert our pre-defined FAQs. This is what we call “Indexing Stage” and each FAQ will be stored with its question embedding in ES.
```
def index_qa_pairs(qa_pairs: List[Dict[str, str]]) -> None:
for qa_pair in qa_pairs:
question = qa_pair["question"]
answer = qa_pair["answer"]
embedding = sentence_transformer.encode(question)[0].tolist()
data = {
"question": question,
"embedding": embedding,
"answer": answer,
}
es_client.index(
index=INDEX_NAME,
body=data
)
qa_pairs = [{
"question": "How do I improve my English speaking? ",
"answer": "Speak more",
},{
"question": "What should I do to earn money online? ",
"answer": "Learn machine learning",
},{
"question": "How can I improve my skills? ",
"answer": "More practice",
}]
index_qa_pairs(qa_pairs)
```
By running the code above, we could simply index three different FAQs with its answer into ES, and then we are ready for our querying stage.
In the querying stage, we need to encode the user question into embedding and construct a customized ES query that computes cosine similarities based on embeddings to rank the pre-defined FAQs.
```
ENCODER_BOOST = 10
def query_question(question: str, top_n: int=10) -> List[dict]:
embedding = sentence_transformer.encode(question)[0].tolist()
es_result = es_client.search(
index=INDEX_NAME,
body={
"from": 0,
"size": top_n,
"_source": ["question", "answer"],
"query": {
"script_score": {
"query": {
"match": {
"question": question
}
},
"script": {
"source": """
(cosineSimilarity(params.query_vector, "embedding") + 1)
* params.encoder_boost + _score
""",
"params": {
"query_vector": embedding,
"encoder_boost": ENCODER_BOOST,
},
},
}
}
}
)
hits = es_result["hits"]["hits"]
clean_result = []
for hit in hits:
clean_result.append({
"question": item["_source"]["question"],
"answer": item["_source"]["answer"],
"score": item["_score"],
})
return clean_result
query_question("How to make my English better?")
```
The customized ES query will contain a “script” field which allows us to define a scoring function that computes the cosine similarity score on embeddings and further combine it to the general ES BM25 matching score. “ENCODER_BOOST” is hyper-parameter we could change to weight the embedding cosine similarity. Further detail on using ES script function could be found here: https://www.elastic.co/blog/text-similarity-search-with-vectors-in-elasticsearch.
By running the “query_question” function with an argument of a specific user question, we can find the most similar FAQs in ES not only based on the keyword match (BM25) but also taking into account it’s textual meaning (SBERT embedding). And this will be the key entry point for a FAQ bot.
Looking Forward
In this tutorial, we have demonstrated a simple way to create an FAQ bot by matching user questions to pre-defined FAQs using SBERT and ES. The solution is very scalable and could achieve decent performance. However, we haven’t gotten the chance to talk about two important pieces of work that could further improve your bot accuracy. First, we could fine-tune SBERT on the domain-specific dataset instead of using the pre-trained one. This in practice could significantly boost the model performance if the text-domain is quite different. Second, this search-based matching approach is usually the first step for a mature system given its low computation cost. Once ES returns a list of candidate FAQs, an additional ranking step could be added to select the best match. This could be done by more complex learn-to-rank models or classification models that take a pair of sentences at a time. We will further illustrate this in future posts.
References
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding
Reimers, N., and Gurevych, I. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global Vectors for Word Representation.