Unlike most resources, data does not diminish in value as it is used. The same data can be used in many places, and the more combinations of data an organization creates—such as between reference data and data from business processes across the enterprise—the more value it can extract via enterprise-wide visibility, real-time analytics, and more accurate AI and ML predictions. Organizations that are good at sharing data internally as legally permissible will realize more value from their data resources than organizations that aren’t.
But like any resource, data risks must be managed, particularly in regulated industries. Controls help to mitigate such risks, so organizations that have strong controls around their data are exposed to less risk than those that don’t.
This presents a paradox: data that is permitted to be freely shareable across the enterprise has the potential to add tremendous value for stakeholders, but the more freely shareable the data is, the greater the possible risk to the organization. To unlock the value of our data, we must solve this paradox. We must make data easy to share across the organization, while maintaining appropriate control over it.
JPMC is taking a two-pronged approach to addressing this paradox. Firstly, by defining ‘Data Products,’ which are curated by people who understand the data and its management requirements, permissible uses and limitations. And secondly, by implementing a ‘Data Mesh’ architecture, which allows us to align our data technology to those data products.
This combined approach:
- Empowers data product owners to make management and use decisions for their data
- Enforces those decisions by sharing data, rather than copying it
- Provides clear visibility of where data is being shared across the enterprise
Let’s first look at what the Data Mesh is, and then at how the Data Mesh architecture supports our Data Product strategy, and how both enable our businesses.
Aligning our Data Architecture to our Data Product Strategy
JPMC is comprised of multiple lines of business (LoBs) and corporate functions (CFs) that span the organization. To enable data consumers across JPMC’s LoBs and CFs to more easily find and obtain the data they need, while providing the necessary control around the use of that data, we are adopting a Data Product strategy.
Data products are groups of related data from the systems that support our business operations. They are broad but cohesive collections of related data. We store the data for each data product in its own product-specific data lake. We provide physical separation between each data product lake. Each lake has its own cloud-based storage layer, and we catalog and schematize the data in each lake using cloud services. One can use cloud based storage and data integration services such as AWS S3 and AWS Glue to provide those storage and cataloguing capabilities.
The services that consume data are hosted in consumer application domains. These consumer applications are physically separated both from each other and from the data lakes. When a data consumer needs data from one or more of the data lakes, we use cloud services to make the lake data visible to the data consumers, and provide other cloud services to query the data directly from the lakes. One could use cloud based lake formation and data cataloging services such as AWS LakeFormation and Glue Catalog to make data visible, and interactive data query services such as AWS Athena to query the data.
The data product-specific lakes that hold data, and the application domains that consume lake data, are interconnected to form the data mesh.
The services that consume data are hosted in consumer application domains. These consumer applications are physically separated both from each other and from the data lakes. When a data consumer needs data from one or more of the data lakes, we use cloud services to make the lake data visible to the data consumers, and provide other cloud services to query the data directly from the lakes. One could use cloud based lake formation and data cataloging services such as AWS LakeFormation and Glue Catalog to make data visible, and interactive data query services such as AWS Athena to query the data
Empower the Right People to Make Control Decisions
Our data mesh architecture allows each data product lake to be managed by a team of data product owners who understand the data in their domain, and who can make risk-based decisions regarding the management of their data.
When a consumer application needs data from a product lake, the team that owns the consumer application locates the data they need in our enterprise-wide data catalog. The entries in the catalog are maintained by the processes that move data to the lakes, so the catalog always reflects what data is currently in the lakes.
The catalog allows the consumption team to request the data. Because each lake is curated by a team who understand the data in their domain and can help facilitate rapid, authoritative decisions by the right decision-makers, the consumption team’s wait time is minimized.
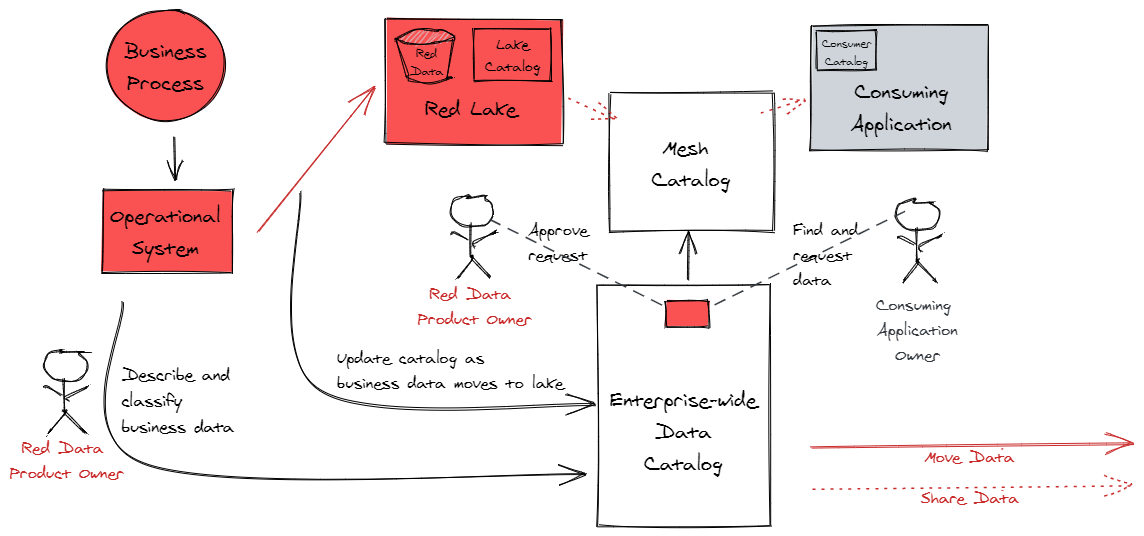
When a consumer application needs data from a product lake, the team that owns the consumer application locates the data they need in our enterprise-wide data catalog. The entries in the catalog are maintained by the processes that move data to the lakes, so the catalog always reflects what data is currently in the lakes.
Enforce Control Decisions Through In-Place Consumption
The data mesh allows us to share data from the product lakes, rather than copying it to the consumer applications that will use it. In addition to keeping the storage bill down, sharing minimizes discrepancies in the data between the system that produced the data and the system that consumes it. That helps to ensure that the data being consumed for analytics, AI/ML, and reporting is up to date and accurate.
And, because the data doesn’t physically leave the lake, it’s easier to enforce the decisions that the data product owners make about their data. For example, if the data product owners decide to tokenize certain types of data in their lake, data consumers can only access the tokenized values. There are no copies of the untokenized data outside of the lake to create a control gap.
In-place consumption requires more sophisticated access control mechanisms than those needed to control access to copied data, though. When data is consumed in-place, we will need to restrict visibility at a very granular level - to specific columns, records, and even to individual values. For example, when a system from one of our lines of business queries a pool of firmwide reference data shared through a lake, that system may only be granted permission to access the reference data that pertains to that line of business.
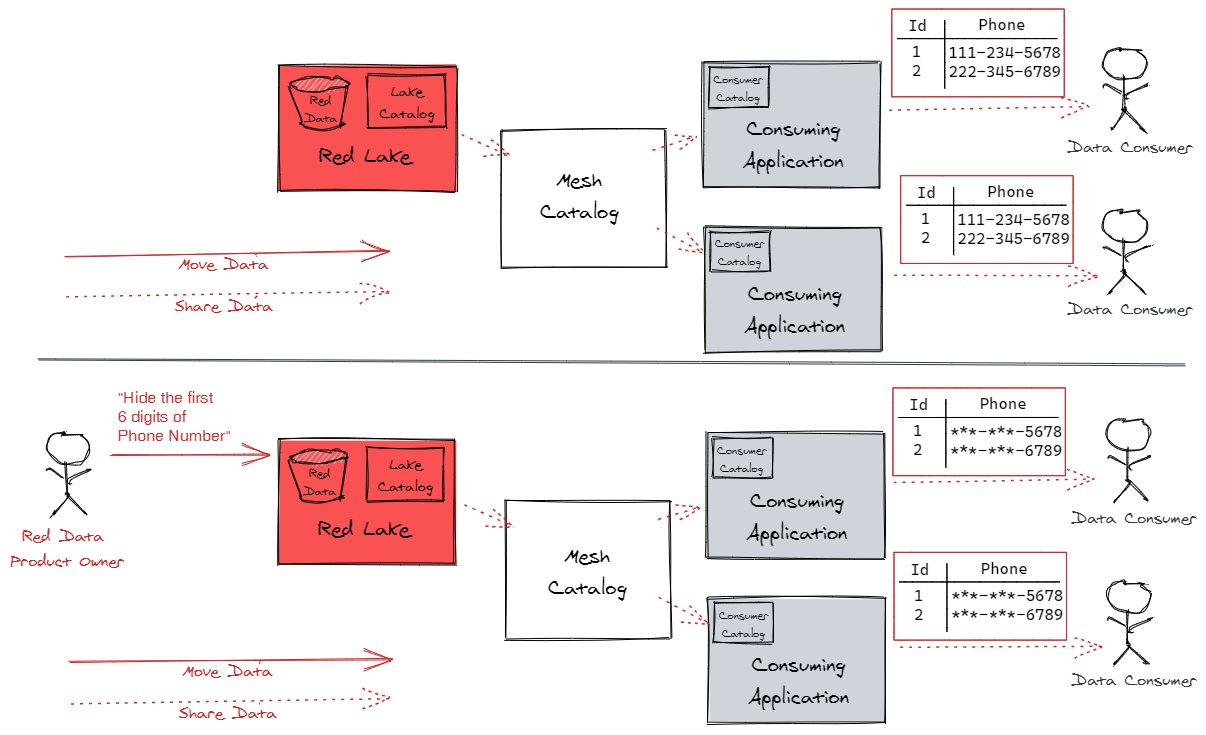
In-place consumption requires more sophisticated access control mechanisms than those needed to control access to copied data, though. When data is consumed in-place, we will need to restrict visibility at a very granular level - to specific columns, records, and even to individual values.
Provide cross-enterprise visibility of data consumption
Historically, data exchanges between systems were either system-to-system or via message queues. Since there was no central, automated repository of all data flows, data product owners couldn’t easily see when their data was flowing between systems.
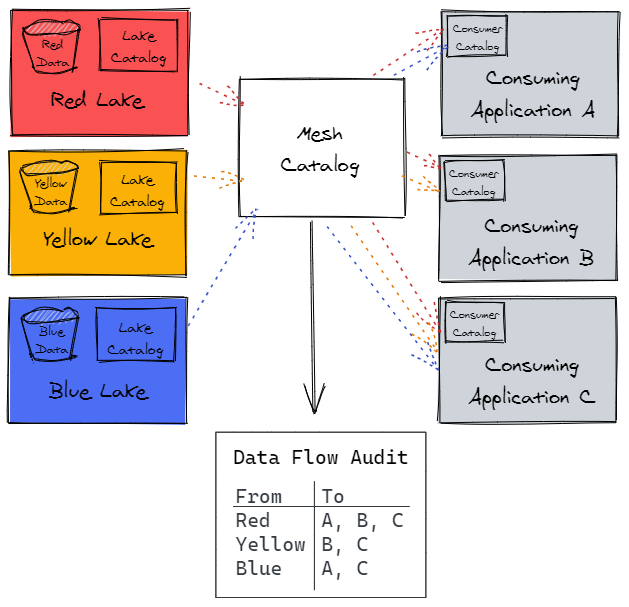
Our data mesh architecture addresses the visibility challenge by using a cloud-based Mesh Catalog to facilitate data visibility between the lakes and the data consumers. One could use AWS Glue Catalog or a similar a cloud based data cataloging service to enable this.
This catalog does not hold any data, but it does have visibility of what lakes are sharing data with which data consumers. This offers a single point of visibility into the data flows across the enterprise, and gives the data product owners confidence that they know where their data is being used.
Data Mesh in Action
Here’s an example to illustrate how the Data Mesh architecture will enable our business.
In the past, teams producing firmwide reports would extract and join data from multiple systems in multiple data domains to produce reports.
Through the Data Mesh architecture, the data product owners for those data domains will make their data available in lakes. The enterprise data catalog will allow reporting teams to find and request the lake-based data to be made available in their reporting application. The mesh catalog will allow auditing the data flows from the lakes to the reporting application, so it’s clear where the data in the reports originates.
Through the Data Mesh architecture, the data product owners for those data domains will make their data available in lakes. The enterprise data catalog will allow reporting teams to find and request the lake-based data to be made available in their reporting application. The mesh catalog will allow auditing the data flows from the lakes to the reporting application, so it’s clear where the data in the reports originates.
Conclusion
JPMC’s data mesh architecture aligns our data technology solutions to our data product strategy. By providing a blueprint for instantiating data lakes that implements the mesh architecture in a standardized way using a defined set of cloud services, we enable data sharing across the enterprise while giving data owners the control and visibility they need to manage their data effectively.